Instance Segmentation per l’Identificazione di Oggetti in Tempo Reale nei Contesti Automobilistici
Introduzione
Negli ultimi anni uno dei principali sforzi di innovazione nel contesto del settore automobilistico è sicuramente l’automazione della guida. Oltre a questo, sono state proposte e sono in sviluppo svariate tecnologie di assistenza alla guida che aiutano a salvare vite umane, a prevenire incidenti e a migliorare l’esperienza di guida anticipando situazioni di rischio e suggerendo o attuando correttive. Queste tecnologie consentono l’identificazione dei rischi per il veicolo, per i passeggeri del veicolo e per qualsiasi altra persona o animale in strada, oltre a determinare le opportune azioni di mitigazione del rischio.
I moderni approcci basati sull’utilizzo delle reti neurali hanno permesso la creazione di modelli sempre più accurati per risolvere problemi di regressione e classificazione. Tra i compiti particolarmente adatti ad essere risolti dalle reti neurali, in particolare le reti neurali convoluzionali che vengono utilizzate prevalentemente per l’elaborazione di immagini, è possibile citare l’object detection, la semantic segmentation e l’instance segmentation.
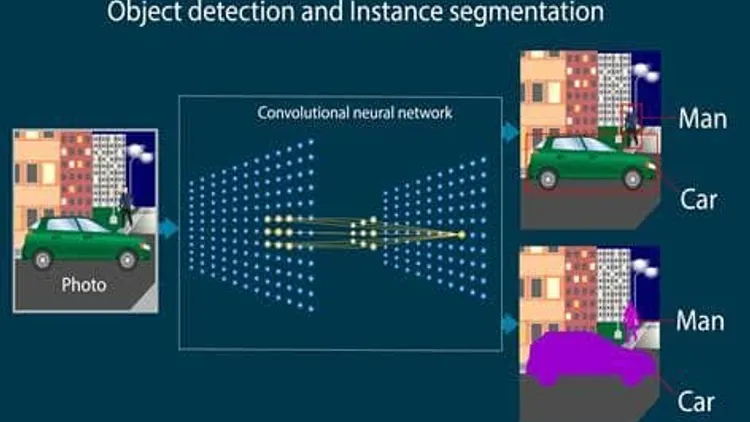
Più precisamente, quando abbiamo un’immagine, un problema di instance segmentation consiste nell’identificare ogni istanza di un singolo oggetto, rilevandone la posizione nell’immagine (object detection) ed identificandone la classe di appartenenza. Questo consente di differenziare ogni istanza da una qualsiasi altra istanza (anche appartenente alla medesima classe). Quest’ultimo aspetto è ciò che distingue un problema di semantic segmentation (che associa solo la stessa classe a tutte le istanze predette, essendo incapace di distinguerle) da un problema di instance segmentation (che invece entra nel merito della individualità e dunque dei confini dei singoli oggetti).
Lo scopo di questa tesi è quello di sviluppare un sistema in grado di effettuare l’instance segmentation, ovvero identificare, classificare e tracciare gli ostacoli nella scena stradale, utilizzando un insieme di dataset generati mediante il simulatore Car Learning To ACT (CARLA) per avere diversi scenari di momenti comuni di guida. Per fare ciò, vengono addestrate reti neurali profonde il cui compito è quello di identificare, in immagini e video forniti come input, aspetti utili alla classificazione, al rilevamento di oggetti, alla presenza o assenza di caratteristiche specifiche. Questo consente di realizzare approcci rivolti alla sicurezza stradale o informare algoritmi di guida autonoma che possono quindi tenere conto della presenza di elementi di specifiche classi di appartenenza durante la guida ed in tempo reale.
Gli approcci di instance segmentation basati su vari algoritmi sono stati comparati su alcuni dataset contenenti sessioni di guida (rappresentati come sequenze di immagini raccolte in un video) e per ciascun modello neurale sono state calcolate le prestazioni finali con le metriche tipicamente utilizzate in questo contesto (relative alla classificazione e sovrapposizione delle regioni di interesse).
Background
Carla Simulator

CARLA è un simulatore open source per la ricerca sulla guida autonoma.
È stato sviluppato da zero per supportare lo sviluppo, l’addestramento e la validazione di sistemi di guida autonoma urbana. Oltre al codice e ai protocolli open-source, CARLA fornisce risorse digitali aperte (layout urbano, edifici, veicoli) che sono stati creati a questo scopo e possono essere utilizzati liberamente.
La piattaforma di simulazione supporta una specificazione flessibile di suite di sensori e condizioni ambientali. Uno degli obiettivi principali di CARLA è quello di aiutare a democratizzare la ricerca e lo sviluppo della guida autonoma, fungendo da strumento facilmente accessibile e personalizzabile dagli utenti.
CARLA vanta una serie impressionante di modelli di sensori del mondo reale come telecamere, LIDAR e RADAR. Il simulatore dà anche accesso a informazioni privilegiate come la segmentazione semantica della verità di base e le informazioni sulla profondità.
Inoltre, CARLA offre una scalabilità tramite un’architettura server multi-client: più client nello stesso nodo o in nodi diversi possono controllare attori diversi. Gli attori di CARLA sono entità che interagiscono all’interno della simulazione come veicoli, pedoni e segnali di traffico.
Machine Learning
Il campo di ricerca che studia algoritmi e sistemi in grado di apprendere dai dati è il Machine Learning, apprendendo una nuova conoscenza. Un sistema con queste caratteristiche, analizzando dati come input, è spesso in grado di mostrare in output dati con un livello di accuratezza vicino a quello desiderato.
È facile intuire come lo studio e lo sviluppo dell’apprendimento automatico siano diventati il punto fondamentale della ricerca sull’Intelligenza Artificiale, trovando soluzioni a compiti molto lunghi ed elaborati. Gli algoritmi di machine learning sono progettati per individuare schemi, classificare oggetti, prevedere risultati e prendere decisioni sulla base di dati acquisiti non necessariamente strutturati.
Possono essere impiegati uno alla volta o combinati, così da ottenere una maggiore precisione nei casi in cui vengano forniti dati complessi e più imprevedibili. Il processo di Machine Learning inizia con la raccolta e la preparazione dei dati, che possono essere numeri, immagini o testo di ogni tipo e provenienti da diverse fonti. Più dati si hanno, e migliore sarà l’affidabilità del risultato.
Un problema comune del Machine Learning è l’overfitting, che si verifica quando un modello di apprendimento automatico si adatta troppo ai dati di addestramento ma risulta poco generalizzabile ad altri casi. L’overfitting può verificarsi per vari motivi, tra cui:
- La dimensione dei dati di addestramento è troppo piccola e non contiene campioni di dati sufficienti per rappresentare in modo accurato tutti i possibili valori dei dati di input.
- I dati di addestramento contengono grandi quantità di informazioni irrilevanti, chiamate dati rumorosi.
- Il modello viene addestrato troppo a lungo su un singolo set di dati campione.
Per risolvere l’overfitting, generalmente si eliminano alcune features dal dataset di training e si elabora un nuovo modello predittivo. Il nuovo modello predittivo ottenuto con meno features è meno preciso rispetto al precedente, ma è più generale, cioè il margine di errore è minore quando lo utilizziamo sui dati di test.
Un altro problema comune del Machine Learning è l’underfitting, uno scenario in data science in cui un modello di dati non riesce a catturare accuratamente la relazione tra le variabili di input e output, generando un alto tasso di errore sia sul set di addestramento che sui dati non visti. Si verifica quando un modello è troppo semplice, il che può essere il risultato di un modello che ha bisogno di più tempo di addestramento, più caratteristiche di input, o meno regolarizzazione.
Dato che questo comportamento può essere osservato durante l’utilizzo del set di addestramento, i modelli sottodimensionati sono solitamente più facili da identificare rispetto a quelli sovradimensionati.
Deep Learning
Una branca del Machine Learning è il Deep Learning, nata con l’obiettivo di imitare le attività e l’apprendimento del cervello umano in maniera più dettagliata attraverso l’utilizzo di un apprendimento su più livelli di astrazione. È caratterizzato dal fatto che i dati, provenienti da un livello precedente, vengono utilizzati come input di quello successivo, estraendo informazioni più complesse con l’aumentare della profondità.
Le tecniche di Deep Learning si basano sulla definizione di nuove architetture di reti neurali artificiali concepite per adattarsi a compiti di elaborazione specifici. Il termine “deep” deriva dal fatto che questi modelli, per eseguire compiti complessi, sono costituiti da un elevato numero di layer concatenati l’uno con l’altro. Questo consente agli strati successivi di analizzare e generare un elevato numero di caratteristiche che, a partire dalle informazioni prodotte dagli strati precedenti, possono essere utilizzate per effettuare compiti di classificazione e regressione.
Uno dei problemi del Deep Learning riguarda la complessità del modello: infatti, man mano che la profondità della rete aumenta, si ha più possibilità di causare overfitting.
Reti neurali
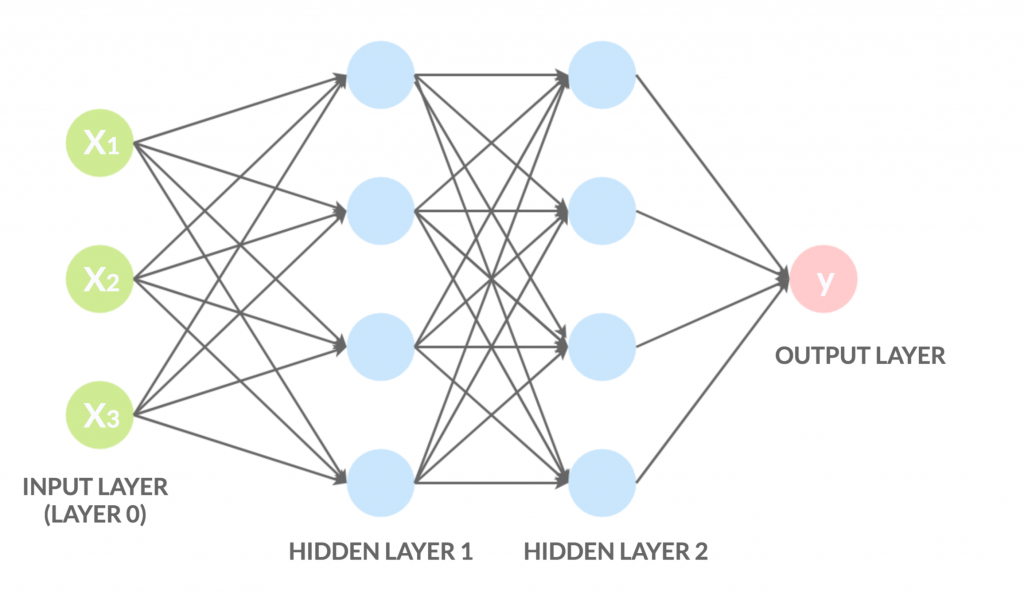
Una rete neurale artificiale è un modello matematico ispirato a una rete neurale biologica, con l’obiettivo di riprodurre le funzioni tipiche del cervello umano. Una rete di questo tipo è realizzata, così come quella biologica, da unità semplici chiamate neuroni artificiali, caratterizzati dal fatto di avere molti ingressi e una sola uscita, calcolata dalla somma pesata degli input.
Come già accennato, le reti, applicate al Deep Learning, sono strutturate su più livelli, dove il grado di profondità ne determina il grado di complessità del calcolo. Nel corso degli anni, sono state realizzate diverse architetture con compiti ben precisi, dando vita a diverse reti neurali artificiali, tra cui il MLP (Multi Layer Perceptron) e la CNN (Convolutional Neural Network).
CNN
Una rete neurale convoluzionale (CNN o ConvNet, dall’inglese convolutional neural network) è un tipo di rete neurale di tipo feed-forward ispirata all’organizzazione della corteccia visiva. La CNN funziona, in generale, come tutte le altre reti feed-forward: è costituita da un blocco di input, uno o più blocchi nascosti (hidden layer), che effettuano calcoli tramite funzioni di attivazione (ad esempio RELU), e un blocco di output che effettua la classificazione vera e propria.
Una rete neurale feed-forward è un tipo di rete neurale artificiale in cui le connessioni tra i nodi non formano cicli. Le informazioni si muovono solo in una direzione, dai nodi d’ingresso, attraverso nodi nascosti (se esistenti), fino ai nodi d’uscita.
La differenza rispetto alle classiche reti feed-forward è rappresentata dalla presenza dei livelli di convoluzione. Le CNN sono costituite da tre tipi principali di livelli:
- Layer convoluzionale: l’elemento costitutivo principale di una CNN. È qui che viene calcolata la convoluzione dell’input sulla base dei valori di uno o più filtri, appresi durante la fase di addestramento.
- Layer di pooling: riduce la dimensione spaziale delle rappresentazioni correnti (i volumi di uno specifico stadio della rete). Questo serve per ridurre il numero di parametri, il tempo computazionale, e per tenere sotto controllo l’overfitting.
- Layer completamente connesso: a ogni livello, la complessità della CNN aumenta, così come la porzione dell’immagine identificata. I primi livelli si concentrano su caratteristiche semplici (ad esempio, colori e contorni), mentre i livelli successivi riconoscono forme più grandi fino all’identificazione finale dell’oggetto.
Le CNN classificano le immagini basandosi su particolari caratteristiche, come i contorni delle figure, le linee orizzontali, verticali, diagonali e altro ancora. Sono uno degli algoritmi di Deep Learning più utilizzati nella computer vision, applicati in diversi campi: dalle automobili autonome ai droni, dalle diagnosi mediche al supporto per gli ipovedenti.
Le CNN furono introdotte per la prima volta nel 1989, ma solo recentemente, grazie all’aumento della potenza delle GPU e alla disponibilità di grandi quantità di dati per l’addestramento, sono state largamente utilizzate nei compiti di computer vision.
La struttura della CNN si ispira alla corteccia visiva degli animali, in cui gruppi di cellule sono sensibili a piccole sottoregioni dell’immagine in ingresso. L’immagine non viene elaborata come un singolo blocco, ma come una composizione di blocchi più piccoli.
Utilizzeremo il termine riconoscimento di oggetti in senso ampio, includendo sia la classificazione delle immagini (determinare quali classi di oggetti sono presenti) sia il rilevamento di oggetti (localizzare tutti gli oggetti presenti nell’immagine).
Mask R-CNN
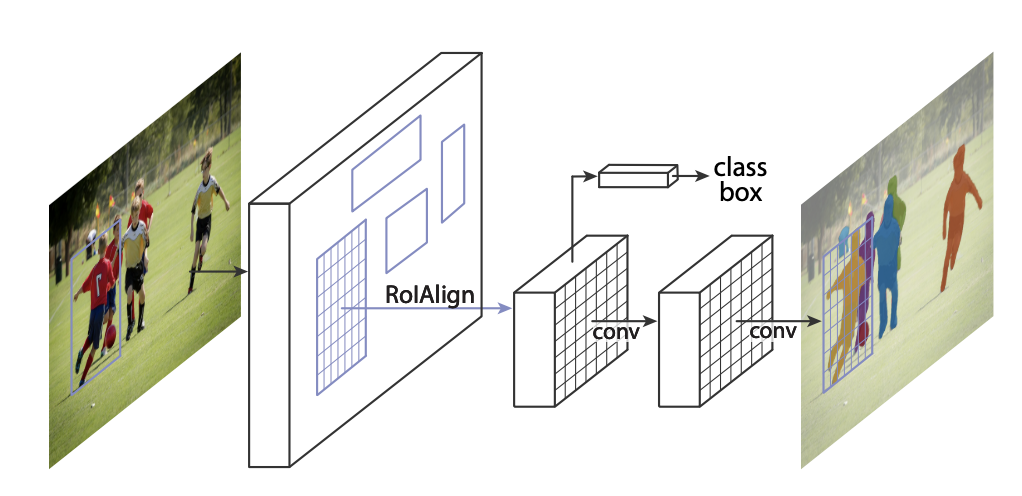
Nel 2014 fu proposta una rete neurale, la Region-based Convolutional Neural Network (R-CNN), che permetteva di risolvere problemi di object detection. Nel corso degli anni, R-CNN venne notevolmente migliorata, con l’introduzione di Fast R-CNN e Faster R-CNN, che hanno superato la versione originale sia in termini di performance che di accuratezza.
Mask R-CNN è un’estensione di Faster R-CNN utilizzata per problemi di instance segmentation. Consente di risolvere la segmentazione delle singole istanze ed è la rete neurale impiegata nell’applicazione. Una rete neurale convoluzionale può essere utilizzata per molteplici obiettivi: dalla classificazione alla segmentazione semantica delle istanze.
La segmentazione semantica consiste nel dividere un’immagine in insiemi di pixel opportunamente etichettati e classificati. Quando è necessario segmentare ogni singola istanza (instance segmentation), l’obiettivo diventa differenziare ogni oggetto identificato (object detection) e classificato, determinandone l’esatta posizione e distinguendolo da qualsiasi altro oggetto, anche appartenente alla stessa classe.
Segmentazione
La segmentazione delle immagini è una parte fondamentale per i sistemi di Computer Vision e consiste nel partizionare un’immagine in diverse regioni, rappresentanti diversi oggetti. Questo processo si basa sull’estrazione, dal dominio dell’immagine, di regioni connesse tra loro.
La segmentazione riveste un ruolo importante in molte applicazioni, come immagini mediche e realtà aumentata. Sono stati sviluppati numerosi algoritmi di segmentazione, dai semplici algoritmi basati su soglie o istogrammi a quelli più avanzati. Si parla di semantic segmentation quando l’algoritmo stabilisce anche la classe di ogni regione individuata.
Negli ultimi anni, le reti di Deep Learning hanno prodotto una nuova generazione di modelli di segmentazione semantica con miglioramenti significativi nelle prestazioni, raggiungendo un’elevata accuratezza.
Proprietà di una buona segmentazione:
- Tutti i pixel devono appartenere ad almeno una regione della partizione.
- I pixel di una regione devono essere connessi.
- Le regioni devono essere separate tra loro.
Tipi di segmentazione:
- Semantic Segmentation: divide l’immagine in blocchi di pixel classificati ed etichettati in una classe specifica.
- Instance Segmentation: identifica, classifica e differenzia ogni singolo oggetto, anche se appartenente alla stessa classe.
- Panoptic Segmentation: combina la segmentazione semantica e l’instance segmentation.
Instance Segmentazione
L’Instance Segmentation è impegnativa perché richiede il rilevamento corretto di tutti gli oggetti in un’immagine e la loro segmentazione. Essa combina elementi classici di visione artificiale come l’Object Detection, in cui l’obiettivo è classificare singoli oggetti e localizzarli utilizzando un bounding box, e la semantic segmentation, in cui l’obiettivo è classificare ciascun pixel in un insieme fisso di categorie senza differenziare le istanze dell’oggetto.
Nonostante la classificazione delle immagini e l’Object Detection possano sembrare molto simili, in realtà sono due tecniche diverse. Mentre la classificazione si occupa di classificare un’immagine in una determinata categoria, l’Object Detection identifica la posizione degli oggetti all’interno di un’immagine. Le due tecniche non sono contrapposte; infatti, si utilizza la classificazione per generare informazioni sull’intera immagine e, successivamente, l’Object Detection riduce progressivamente la regione dell’immagine fino a ottenere un riquadro ben specifico al quale viene associata un’etichetta.
La Precision-Recall curve (PR) è una metrica utilizzata per valutare le prestazioni dei modelli di classificazione, compresi quelli utilizzati in Mask R-CNN, un tipo di modello di segmentazione e rilevamento oggetti. Per comprendere la curva Precision-Recall in Mask R-CNN, è necessario avere una comprensione di base dei seguenti concetti:
- Precision: La precisione misura la frazione di istanze positive (oggetti rilevati) che sono state correttamente identificate dal modello rispetto al totale delle istanze identificate come positive. In altre parole, indica quanti degli oggetti identificati come positivi dal modello sono effettivamente oggetti veri positivi.
[Prec = \frac{Tp}{Tp+Fp}]
- **TP (True Positives)**: Oggetti veri positivi (oggetti rilevati correttamente).
- **FP (False Positives)**: Oggetti falsi positivi (oggetti identificati erroneamente come positivi).- Recall: La recall, nota anche come sensibilità o tasso di vera positività, misura la frazione di istanze positive che sono state correttamente identificate dal modello rispetto al totale delle istanze positive effettive. In altre parole, indica quanti degli oggetti positivi veri sono stati rilevati dal modello.
$$ \text{Recall} = \frac{TP}{TP + FN} $$
- **FN (False Negatives)**: Oggetti falsi negativi (oggetti non rilevati).La Precision-Recall curve è creata variando la soglia di confidenza del modello per la classificazione degli oggetti. Per ogni valore della soglia, il modello può produrre un diverso set di predizioni positive e quindi calcolare la precisione e il richiamo corrispondenti. Si effettua il plot di questi punti per varie soglie e così si crea la curva PR. Questa curva fornisce una rappresentazione della trade-off tra la precisione e il richiamo del modello a diverse soglie di confidenza.
Average Precision
L’AP è una metrica che misura la precisione media delle previsioni di istanze. È spesso calcolato a diverse soglie di IOU e quindi aggregato per ottenere un valore complessivo. Viene utilizzato per valutare la precisione delle previsioni a varie soglie di sovrapposizione. L’Average Precision è stata calcolata con un IOU del 50%.
L’indice di sovrapposizione (IoU) viene calcolato utilizzando la formula:
$$ IOU= \frac{\text{Area di Sovrapposizione}}{\text{Area di Unione}} $$
L’IoU restituisce un valore compreso tra 0 e 1, dove 1 indica una perfetta sovrapposizione tra le maschere previste e di riferimento, mentre 0 indica nessuna sovrapposizione.
Confusion Matrix
La matrice di confusione è una metrica comunemente utilizzata per valutare le prestazioni dei modelli di classificazione, ma può anche essere adattata per valutare i modelli di instance segmentation in modo più generale. Tuttavia, la segmentazione di istanze è una sfida più complessa rispetto alla classificazione, poiché coinvolge la previsione delle maschere pixel per pixel per diverse istanze di oggetti all’interno di un’immagine. Pertanto, la matrice di confusione può essere meno diretta in questo contesto, ma può ancora fornire informazioni utili.
La confusion matrix è composta da classi di oggetto e background, in cui distinguerà le diverse classi di oggetti (come automobili, persone, animali, ecc.) e adatterà la matrice di confusione per considerare le diverse classi. La matrice conterà il numero di pixel previsti correttamente ed erroneamente per ciascuna classe e per lo sfondo (background).
Mean Average Precision e Mean Average Recall
Il mean Average Precision è una metrica più completa che tiene conto sia della precisione che del recall del modello. Calcola la precisione media per diverse fasce di recall (punti di taglio) e quindi calcola la media di queste precisioni. La precisione misura la proporzione di istanze rilevate che sono vere (cioè la proporzione di istanze segmentate correttamente) rispetto al totale delle istanze rilevate.
Il mean Average Recall è una metrica che valuta la capacità di un modello di segmentazione delle istanze di recuperare correttamente tutte le istanze degli oggetti in una scena. Per calcolare il mAR, si calcola prima il recall per ogni classe di oggetti e quindi si calcola la media di questi recall. Misura la capacità del modello di trovare tutte le istanze di una classe.
In breve, il mAR valuta la capacità di rilevare correttamente tutte le istanze, mentre il mAP considera sia la capacità di rilevare tutte le istanze che la precisione delle rilevazioni. Entrambe le metriche sono importanti per valutare le prestazioni dei modelli di segmentazione delle istanze, e i valori ideali variano a seconda del contesto dell’applicazione.
F-Score
L’F-score, o punteggio F, è una metrica di valutazione comunemente utilizzata per misurare la precisione e il richiamo di un modello di instance segmentation. Questa metrica è particolarmente utile quando si tratta di problemi di segmentazione di istanze, in cui l’obiettivo è individuare e distinguere diverse istanze di oggetti all’interno di un’immagine.
L’F-score è una combinazione di due metriche principali:
- Precision
- Recall
L’F-score combina queste due metriche per ottenere un singolo punteggio che tiene conto sia della precisione che del richiamo. È definito come la media armonica tra precisione e richiamo:
$$ F= \frac{2 \cdot Precision \cdot Recall}{Precision + Recall} $$
L’uso dell’F-score è utile perché bilancia la precisione e il richiamo, fornendo una valutazione complessiva delle prestazioni del modello di instance segmentation. Un punteggio F elevato indica una buona capacità del modello di identificare e distinguere le istanze di oggetti, mentre un punteggio basso può indicare problemi di sovrapposizione, sotto-segmentazione o sovra-segmentazione delle istanze.
Soluzione proposta
.
Architettura

Come primo blocco dell’architettura si ha l’inserimento di un video in input, i video utilizzati fanno parte del Dataset CARLA Binary Single Pedestrian. Nel secondo blocco si effettua l’analisi del video tramite la CNN, nel nostro caso utilizzeremo Mask R-CNN. Un componente fondamentale di Mask R-CNN è la Region Proposal Network, la sua funzione è quella di esaminare la mappa delle caratteristiche e proporre regioni che potrebbero contenere oggetti (Region of Interest o RoI).
Queste proposte di regioni vengono poi passate al resto della rete per la classificazione e la regressione del box delimitatore. Quindi, RPN svolge un ruolo cruciale nel determinare quali parti dell’immagine dovrebbero essere esaminate più attentamente per il rilevamento degli oggetti.
L’operazione di ROI Align estrae una piccola mappa delle caratteristiche da ogni RoI (Region of Interest) nei compiti di rilevamento e segmentazione.
RoIAlign rimuove la quantizzazione severa, allineando correttamente le caratteristiche estratte con l’input.
L’output del ROI Align verrà passato ai diversi layer ed avremo:
- Il layer di classificazione è responsabile della previsione della classe di un oggetto proposto. Questo layer utilizza queste caratteristiche per prevedere la classe dell’oggetto.
- Il layer di regressione è responsabile della previsione del box delimitatore per un oggetto proposto. Questo layer utilizza queste caratteristiche per prevedere le coordinate del box delimitatore.
- Il layer di segmentazione è responsabile della generazione di una maschera per ogni regione di interesse (RoI), segmentando così un’immagine in modo pixel per pixel. Questo layer fornisce una mappa delle caratteristiche per ogni RoI e utilizza queste caratteristiche per generare una maschera.
Dataset CARLA
Il Dataset di CARLA utilizzato è il Binary Single Pedestrian che contiene 400 video, ciascuno della durata di 30 secondi. I dati sono stati generati utilizzando il simulatore CARLA 0.9.13. I video rappresentano quadri di simulazione realistici che possono offrire molti vantaggi rispetto ai dati reali.
Uno dei vantaggi è che è relativamente facile generare una grande quantità di campioni, mentre i dati del mondo reale sono spesso limitati e, per forza di cose, sbilanciati. Di solito le situazioni più pericolose si verificano raramente, e la raccolta di un numero sufficiente di esempi per garantire che il sistema le gestisca correttamente può essere molto difficile.
Quanto spesso si riesce a registrare un bambino che gioca con il cane accanto alla strada? La generazione di questi casi angolari e contraddittori è l’ambito in cui i metodi di simulazione possono essere più utili. Tuttavia, anche i risultati più “tipici” della simulazione possono essere utili, immaginare di avere una quantità illimitata di dati da utilizzare per l’addestramento preliminare dei modelli o la convalida del flusso.

Figura 1: Fotogramma di uno dei video del dataset
MS COCO
Il dataset MS COCO (Microsoft Common Objects in Context) è un dataset su larga scala per il rilevamento di oggetti, la segmentazione, il rilevamento di punti chiave e la creazione di didascalie. Il dataset è composto da 328K immagini.
La prima versione del dataset MS COCO è stata rilasciata nel 2014. Conteneva 164K immagini suddivise in training (83K), validation (41K) e test (41K).
Sulla base del feedback della comunità, nel 2017 la suddivisione training/validation è stata modificata da 83K/41K a 118K/5K. La nuova suddivisione utilizza le stesse immagini e annotazioni e contiene un nuovo set di dati non annotato di 123K immagini.
Il set di dati contiene annotazioni per rilevamento degli oggetti: bounding box e maschere di segmentazione per istanza con 80 categorie di oggetti, segmentazione completa della scena, con 80 categorie di cose (come persona, bicicletta, elefante) e un sottoinsieme di 91 categorie di cose (erba, cielo, strada).
Per l’addestramento del nostro dataset sono stati utilizzati i pesi pre-addestrati del dataset COCO, noto anche come “fine-tuning”, un processo comune nel machine learning e nella visione artificiale. Ecco come funziona:
- Caricamento dei pesi pre-addestrati: i pesi pre-addestrati del dataset COCO vengono caricati nel modello. Questi pesi sono il risultato dell’addestramento del modello su un grande numero di immagini contenute nel dataset COCO.
- Adattamento del modello: il modello viene quindi adattato per lavorare con il nuovo dataset. Questo può includere la modifica dell’ultimo strato della rete per corrispondere al numero di classi nel nuovo dataset.
- Fine-tuning: il modello viene quindi addestrato sul nuovo dataset, ma invece di iniziare con pesi casuali, il modello inizia con i pesi pre-addestrati del dataset COCO. Durante questo processo di addestramento, i pesi del modello vengono aggiornati in modo da minimizzare l’errore sul nuovo dataset.
L’uso dei pesi pre-addestrati del dataset COCO può aiutare a migliorare le prestazioni del modello, specialmente quando il nuovo dataset è relativamente piccolo. Questo perché i pesi pre-addestrati contengono già informazioni utili apprese dal modello durante l’addestramento sul grande e vario dataset COCO.
Object Detection
Il rilevamento degli oggetti esegue la classificazione e la localizzazione anche di immagini con più oggetti di classi diverse. L’attività di localizzazione si ottiene disegnando dei riquadri intorno agli oggetti, generalmente definiti in termini di centro, larghezza e altezza.
All’interno di ciascun riquadro, l’oggetto viene anche classificato.

Figura 1: Fotogramma del video restituito dal simulatore CARLA
Processi
Prima di arrivare al risultato finale con l’individuazione dell’oggetto, ci sono diversi processi che il software effettua. I processi che permettono l’individuazione dell’oggetto sono:
- Anchor Sorting
- Bounding Box Refinement
- Mask Generation
- Layer activations
- Risultato finale
Anchor Sorting

Figura 2: Anchor sorting di un fotogramma estratto dai video analizzati
Gli algoritmi di rilevamento degli oggetti di solito campionano un gran numero di regioni nell’immagine di input, determinano se queste regioni contengono oggetti di interesse e regolano i confini delle regioni in modo da prevedere con maggiore precisione i riquadri di delimitazione degli oggetti. Diversi modelli possono adottare diversi schemi di campionamento delle regioni. L’anchor sorting genera più caselle di delimitazione con scale e rapporti di aspetto diversi, centrate su ciascun pixel.
Gli anchor vengono ordinati e filtrati durante la fase di Region Proposal Network (RPN). Questo processo visualizza ogni passo della prima fase della RPN e mostra gli anchor positivi e negativi insieme alla rifinitura del box dell’anchor.
Gli anchor “positivi” sono quelli che hanno un’intersezione su unione (IoU) elevata con un ground truth box, o che hanno la massima IoU con un ground truth box. Questi sono considerati come contenenti l’oggetto di interesse.
Gli anchor “negativi” sono quelli che hanno una bassa IoU con tutti i ground truth box. Questi sono considerati come non contenenti l’oggetto di interesse.
La rifinitura del box dell’anchor è un processo in cui le coordinate degli anchor vengono leggermente modificate per adattarsi meglio all’oggetto di interesse.
Bounding Box Refinement
La fase di “Bounding Box Refinement” in Mask R-CNN è una parte del processo di rilevazione degli oggetti ed è responsabile di perfezionare le posizioni delle bounding box inizialmente proposte dal modello per ciascuna istanza dell’oggetto rilevato. Questa fase è una delle caratteristiche chiave di Mask R-CNN ed è utile per migliorare la precisione della localizzazione degli oggetti.

Figura 3: Bounding Box Refinement di un fotogramma estratto dai video analizzati
Mask Generation
La fase di “mask generation” in un modello Mask R-CNN si riferisce al processo in cui il modello genera maschere binarie pixel-wise per ciascuna istanza dell’oggetto rilevato nell’immagine. Questa è una parte fondamentale del processo di “instance segmentation”, che combina la rilevazione degli oggetti con la segmentazione pixel-wise.
La capacità di generare maschere pixel-wise per le istanze degli oggetti è ciò che distingue Mask R-CNN da altri modelli di rilevazione degli oggetti. Questo è particolarmente utile in applicazioni in cui è necessario distinguere e analizzare oggetti sovrapposti o vicini, come nell’ambito della visione artificiale avanzata e dell’analisi delle immagini mediche.

Figura 4: Mask Generation di un fotogramma estratto dai video analizzati
Layer activations

Figura 5: Layer activations di un fotogramma estratto dai video analizzati
Le attivazioni di un layer in Mask R-CNN rappresentano le informazioni estratte dall’immagine in punti specifici del processo di elaborazione. Queste informazioni sono fondamentali per il rilevamento degli oggetti e per la segmentazione, poiché contengono dettagli sulle caratteristiche degli oggetti nell’immagine.
Risultato finale
Alla fine, il modello fornisce il risultato finale che comprende le seguenti informazioni per ciascuna regione proposta:
- La classe dell’oggetto rilevato.
- Le coordinate della bounding box che circonda l’oggetto.
- La maschera di segmentazione pixel-per-pixel che identifica l’area esatta dell’oggetto nell’immagine.

Figura 6: Risultato finale di un fotogramma estratto dai video analizzati
Risultati ed analisi
Introduzione
La validazione di qualsiasi approccio di segmentazione delle istanze è un passo fondamentale nella valutazione della sua efficacia e robustezza, in particolare se applicato ad ambienti complessi e dinamici. Nel campo della visione artificiale, la segmentazione delle istanze è un compito fondamentale che coinvolge non solo l’identificazione di oggetti all’interno di un flusso di immagini o video, ma anche la differenziazione delle singole istanze di tali oggetti. Questa distinzione è cruciale per numerose applicazioni del mondo reale, tra cui la guida autonoma, la sorveglianza e la robotica, dove la localizzazione e il tracciamento precisi degli oggetti svolgono un ruolo centrale nei sistemi decisionali e di controllo.
In questo capitolo presentiamo i risultati della nostra valutazione completa di un approccio di segmentazione delle istanze, particolarmente adattato alle sfide uniche degli scenari dinamici in tempo reale. Per valutare rigorosamente le prestazioni di questo approccio, utilizziamo due distinti set di dati comprendenti sequenze video generate utilizzando il simulatore CARLA. La scelta di utilizzare CARLA deriva dal fatto che, oltre ad essere una piattaforma di simulazione open-source, consente di ricreare ambienti urbani complessi con interazioni realistiche di veicoli e pedoni, rendendola la scelta ideale per valutare modelli di segmentazione delle istanze in contesti dinamici e reali.
L’obiettivo di questa valutazione è valutare la capacità del nostro approccio alla segmentazione delle istanze di rilevare e segmentare in modo accurato ed efficiente gli oggetti nelle scene complesse del simulatore CARLA. Valutiamo le sue prestazioni in termini di precisione, richiamo e identificazione delle istanze, con un focus specifico sulla sua adattabilità a diversi scenari, come condizioni meteorologiche variabili, diversi ambienti di illuminazione e un’ampia gamma di tipi di oggetti e interazioni.
Questo capitolo è organizzato come segue: introduciamo innanzitutto in dettaglio i due set di dati utilizzati per la valutazione, sottolineando l’importanza di scenari diversi e stimolanti. Descriviamo quindi la nostra configurazione sperimentale e le metriche di valutazione impiegate per quantificare le prestazioni dell’approccio. Infine, presentiamo e discutiamo i risultati della valutazione, traendo conclusioni sui punti di forza e sui limiti dell’approccio di segmentazione delle istanze e sulle sue potenziali implicazioni per le applicazioni del mondo reale nella guida autonoma ed oltre. L’obiettivo di questa valutazione è fornire preziose informazioni sullo stato dell’arte della segmentazione delle istanze per scenari dinamici e reali.
Creazione Dataset
I dataset contengono ognuno 80 frame per ogni video analizzato, sono stati analizzati 4 video per Dataset, il primo dataset contiene frame di eventi quotidiani ed il secondo contiene dei frame dove il software ha avuto delle difficoltà nel riconoscimento dell’oggetto, come il passaggio delle persone dietro altri oggetti.
Le annotazioni di verità sono state create tramite VIA (VGG Image Annotator).
I dati sono stati divisi in due set: il set di addestramento (train) e il set di validazione (val), come di seguito specificato:
- Train set: Questa contiene la maggior parte dei dati ed è utilizzata per addestrare il modello. Include le caratteristiche (features) e le etichette (labels) dei dati.
- Validation set: Questa contiene una porzione più piccola di dati che non viene utilizzata durante l’addestramento. Serve per validare le prestazioni del modello durante e dopo l’addestramento. Anche qui, sono presenti sia le caratteristiche che le etichette.
Nella tabella seguente sono elencati tutti i dati dei Dataset:
| Dati | Dataset “Facile” | Dataset “Complesso” |
|---|---|---|
| Video analizzati | 4 | 4 |
| Durata singolo video | 30 sec | 30 sec |
| Frame per video | 80 | 80 |
| Numero Label | 3 | 4 |
| Label | BG, person, car | BG, traffic-light, car, person |
| Immagini totali | 320 | 320 |
Divisione del Dataset
La divisione dei dati in questi due set aiuta a prevenire il sovradattamento (overfitting), che si verifica quando un modello impara così bene i dati di addestramento da non riuscire a generalizzare bene su nuovi dati. Nei dataset creati, la cartella Train contiene 320 immagini e la cartella Val contiene 70 immagini per ciascun dataset. Il dataset “complesso” contiene immagini in cui gli oggetti sono presenti in forme e situazioni più complesse da riconoscere.
Immagini Essemplificative
Nelle Figure 1-2 sono mostrate alcune immagini esemplificative del dataset “facile”, mentre nelle Figure 3-4 sono mostrate alcune immagini esemplificative del dataset “complesso”.
Dataset “Facile”
 Figura 1: Immagine del Dataset “facile”
Figura 1: Immagine del Dataset “facile”
 Figura 2: Immagine del Dataset “facile”
Figura 2: Immagine del Dataset “facile”
Dataset “Complesso”
 Figura 3: Immagine del Dataset “complesso”
Figura 3: Immagine del Dataset “complesso”
 Figura 4: Immagine del Dataset “complesso”
Figura 4: Immagine del Dataset “complesso”
Training
Il processo di training di una rete neurale per la segmentazione di istanza è un compito complesso che mira a identificare oggetti individuali in un’immagine e assegnare loro un’etichetta unica, creando una maschera di segmentazione per ciascun oggetto. Questo è un passo fondamentale in applicazioni di computer vision come il riconoscimento degli oggetti e la guida autonoma. Ecco una panoramica del processo di training:
-
Raccolta dei dati: Il primo passo è raccogliere un ampio dataset di addestramento che contenga immagini etichettate con maschere di segmentazione per oggetti individuali. Ogni istanza di oggetto deve essere etichettata in modo univoco.
-
Preparazione dei dati: Le immagini e le etichette di segmentazione devono essere preparate per l’addestramento. Questo può includere la riduzione delle dimensioni delle immagini, la normalizzazione dei dati e la divisione del dataset in insiemi di addestramento, convalida e test.
-
Scelta dell’architettura della rete: Si seleziona un’architettura di rete neurale profonda adatta al compito di segmentazione di istanza. Le reti neurali convoluzionali (CNN) sono comunemente utilizzate per questo scopo. Un’architettura popolare è la Mask R-CNN.
-
Inizializzazione dei pesi: I pesi della rete vengono inizializzati, solitamente utilizzando pesi preaddestrati da modelli di riconoscimento degli oggetti o segmentazione semantica.
-
Definizione della funzione di perdita: Viene definita una funzione di perdita che misura l’errore tra le maschere di segmentazione predette e quelle reali. La funzione di perdita include spesso termini per la segmentazione dell’oggetto e per la localizzazione dell’oggetto.
-
Addestramento: La rete viene addestrata utilizzando il dataset di addestramento. Durante l’addestramento, i pesi della rete vengono aggiornati mediante ottimizzazione, solitamente tramite algoritmi come il gradiente stocastico discendente (SGD).
-
Validazione: Periodicamente, la rete viene valutata su un insieme di dati di convalida per monitorare le prestazioni e l’addestramento può essere interrotto quando il modello raggiunge un livello accettabile di precisione.
-
Test: Dopo l’addestramento, il modello viene valutato su un insieme di dati di test per valutare le sue prestazioni in modo imparziale.
-
Iperparametri: Durante il processo di training, è possibile ottimizzare gli iperparametri del modello, come il tasso di apprendimento e il batch size, per migliorare le prestazioni.
-
Inferenza: Una volta addestrata, la rete può essere utilizzata per effettuare l’inferenza su nuove immagini, identificando e segmentando oggetti di istanza.
-
Post-elaborazione: In alcuni casi, possono essere applicate tecniche di post-elaborazione per migliorare ulteriormente la precisione delle maschere di segmentazione.
Come si vede, il processo di training di una rete per la segmentazione di istanza richiede tempo, dati di alta qualità e potenza di calcolo. Tuttavia, quando addestrata con successo, una rete di questo tipo può essere utilizzata in una varietà di applicazioni di computer vision per identificare e segmentare oggetti in immagini in modo accurato.
Parametri Significativi per l’Addestramento di un Modello Mask R-CNN
I parametri più significativi per l’addestramento di un modello Mask R-CNN sono:
- RPN ANCHOR SCALES: Questi sono i rapporti di aspetto degli anchor box utilizzati nella Rete di Proposta di Regioni (RPN). Questi possono essere regolati in base alle dimensioni degli oggetti che si prevede di rilevare.
- TRAIN ROIS PER IMAGE: Questo è il numero di Regioni di Interesse (RoI) da utilizzare per l’addestramento per immagine. Un numero maggiore può migliorare l’accuratezza, ma aumenterà anche il tempo di addestramento.
- MAX GT INSTANCES: Questo è il numero massimo di istanze Ground Truth per immagine.
- POST NMS ROIS INFERENCE e POST NMS ROIS TRAINING: Questi sono il numero di RoI da mantenere dopo la Non-Maximum Suppression (NMS) durante l’inferenza e l’addestramento, rispettivamente.
- Batch size, learning rate e momentum: Questi parametri del SGD optimizer possono avere un impatto significativo sulle prestazioni del modello.
Nell’immagine seguente sono elencati tutti i parametri utilizzati.
Figura 1: Parametri utilizzati per il training
Training
Ciascun modello ottenuto in questa fase è stato ottenuto dopo 100 epoche di training, ciascuna avente 100 steps per epoca.
Codice del Training
# Codice del training
def train(model):
"""Train the model."""
# Training dataset.
dataset_train = CustomDataset()
dataset_train.load_custom("/home/vincenzo/Mask-R-CNN-using-Tensorflow2
/Dataset", "train")
dataset_train.prepare()
# Validation dataset
dataset_val = CustomDataset()
dataset_val.load_custom("/home/vincenzo/Mask-R-CNN-using-Tensorflow2
/Dataset", "val")
dataset_val.prepare()
model.train(dataset_train, dataset_val,
learning_rate=config.LEARNING_RATE,
epochs=100,
layers='heads', #layers='all',
augmentation = imgaug.augmenters.Sequential([
imgaug.augmenters.Fliplr(1),
imgaug.augmenters.Flipud(1),
imgaug.augmenters.Affine(rotate=(-45, 45)),
imgaug.augmenters.Affine(rotate=(-90, 90)),
imgaug.augmenters.Affine(scale=(0.5, 1.5)),
imgaug.augmenters.Crop(px=(0, 10)),
imgaug.augmenters.Grayscale(alpha=(0.0, 1.0)),
imgaug.augmenters.AddToHueAndSaturation((-20, 20)), # change hue and saturation
imgaug.augmenters.Add((-10, 10), per_channel=0.5), # change brightness of images (by -10 to 10 of original value)
imgaug.augmenters.Invert(0.05, per_channel=True), # invert color channels
imgaug.augmenters.Sharpen(alpha=(0, 1.0), lightness=(0.75, 1.5)), # sharpen images
]
))Analisi delle Performance dei Modelli Ottenuti
Le metriche prese in considerazione per la valutazione delle performance sono le medesime utilizzate per misurare le performance del già citato MS-COCO, ovvero Intersection over Union (IoU), Precision e Recall, utilizzate per calcolare i valori di Average Precision e Average Recall.
I dataset considerati per valutare le performance di ciascun modello sono il validation set e il test set. Pertanto, sarà necessario confrontare le bounding box e le segmentation masks ottenute per ciascuna istanza con i loro valori ground truth.
Calcolo Precision-Recall Curve
Nella figura sottostante è mostrato il codice che permette il plot della Precision-Recall curve.
L’Average Precision è stata calcolata con il valore di IoU impostato al 50%. Nel primo dataset è possibile vedere che si ha l’Average Precision uguale a 0.667, mentre nel secondo dataset, composto da video con situazioni complesse per l’identificazione degli oggetti, si ha l’Average Precision uguale a 0.333.
def compute_ap(gt_boxes, gt_class_ids, gt_masks,
pred_boxes, pred_class_ids, pred_scores, pred_masks,
iou_threshold=0.5):
"""Compute Average Precision at a set IoU threshold (default 0.5).
Returns:
mAP: Mean Average Precision
precisions: List of precisions at different class score thresholds.
recalls: List of recall values at different class score thresholds.
overlaps: [pred_boxes, gt_boxes] IoU overlaps.
"""
# Get matches and overlaps
gt_match, pred_match, overlaps = utils.compute_matches(
gt_boxes, gt_class_ids, gt_masks,
pred_boxes, pred_class_ids, pred_scores, pred_masks,
iou_threshold)
# Compute precision and recall at each prediction box step
precisions = np.cumsum(pred_match > -1) / (np.arange(len(pred_match)) + 1)
recalls = np.cumsum(pred_match > -1).astype(np.float32) / len(gt_match)
# Pad with start and end values to simplify the math
precisions = np.concatenate([[0], precisions, [0]])
recalls = np.concatenate([[0], recalls, [1]])
# Ensure precision values decrease but don't increase. This way, the
# precision value at each recall threshold is the maximum it can be
# for all following recall thresholds, as specified by the VOC paper.
for i in range(len(precisions) - 2, -1, -1):
precisions[i] = np.maximum(precisions[i], precisions[i + 1])
# Compute mean AP over recall range
indices = np.where(recalls[:-1] != recalls[1:])[0] + 1
mAP = np.sum((recalls[indices] - recalls[indices - 1]) *
precisions[indices])
return mAP, precisions, recalls, overlaps
AP, precisions, recalls, overlaps = utils.compute_ap(gt_bbox, gt_class_id, gt_mask,
r['rois'], r['class_ids'], r['scores'], r['masks'])
visualize.plot_precision_recall(AP, precisions, recalls)
In questo caso, il codice Python mostra come calcolare la Precision-Recall curve e come ottenere l’Average Precision per un dato valore di IoU. La funzione compute_ap calcola le metriche di precisione e recall per ciascun box di previsione, e il grafico finale viene creato utilizzando la funzione visualize.plot_precision_recall.
Confusion Matrix
Per la confusion matrix è stata utilizzata la funzione multilabel confusion matrix della libreria scikit-learn, che calcola una matrice di confusione per ogni classe o campione. Questa funzione restituisce una matrice di confusione 2x2 corrispondente a ciascun output in input.
from sklearn.metrics import multilabel_confusion_matrix, ConfusionMatrixDisplay
import matplotlib.pyplot as plt
# Calcola la confusion matrix per ogni classe
confusion_matrices = multilabel_confusion_matrix(gt_tot, pred_tot)
# Visualizza ogni confusion matrix
for confusion_matrix in confusion_matrices:
disp = ConfusionMatrixDisplay(confusion_matrix, display_labels=gt_tot)
disp.plot(include_values=True, cmap="ocean_r", ax=None, xticks_rotation="vertical")
plt.show()
# Dataset di esempio
datasets = {
'Dataset 1': {
"class Bg" : np.array([[269, 41], [42, 0]]),
"class Person" : np.array([[235, 0], [1, 116]]),
"class Car" : np.array([[117, 42], [40, 153]])
},
'Dataset 2': {
"class Bg" : np.array([[32, 67], [40, 0]]),
"class Traffic_light" : np.array([[124, 0], [15, 0]]),
"class Car" : np.array([[109, 0], [30, 0]]),
"class Person" : np.array([[45, 40], [22, 30]])
}
}
print(datasets)
# Calcola la Precision, Recall e F1-Score per ogni classe
for (l,d) in datasets.items():
print(l)
p_avg=[]
r_avg=[]
f_avg=[]
for elem in d.keys():
print("\t"+elem)
cm = d.get(elem)
tp = cm[0][0] + cm[1][1]
tpfp = tp + cm[0][1]
tpfn = tp + cm[1][0]
prec = tp / tpfp
p_avg.append(prec)
rec = tp / tpfn
r_avg.append(rec)
f1score = 2*prec*rec/(prec+rec)
f_avg.append(f1score)
print ('\tPrecision: {}\n\tRecall: {}\n\tF1-score:{}'.format(prec, rec, f1score))
print(50*'-')
print("Precision average:", np.average(p_avg))
print("Recall average:", np.average(r_avg))
print("F1-Score average:", np.average(f_avg))
print()Immagini delle Precision-Recall Curve
Di seguito sono riportate le curve Precision-Recall per i due dataset:

Figura 1: Precision Recall curve ed AP del primo dataset
Figura 2: Precision Recall curve ed AP del secondo dataset
Questo codice Python calcola la precision, recall, e F1-score per ogni classe nei due dataset, quindi visualizza queste metriche e le confusion matrices. Viene anche calcolata la media di queste metriche per ogni dataset, permettendo una valutazione complessiva delle performance del modello per ciascun set di dati.
In aggiunta, puoi usare le immagini delle Precision-Recall curve per rappresentare visivamente i risultati ottenuti per i due dataset.
- Per la label BG del primo dataset la confusion matrix è la seguente:

Figura 1: Confusion Matrix BG del primo dataset
Per la label BG si ha:
- Precision: 0.867
- Recall: 0.864
- F1-score: 0.866
- Per la label Person del primo dataset la confusion matrix è la seguente:

Figura 2: Confusion Matrix Person del primo dataset
Per la label Person si ha:
- Precision: 1.0
- Recall: 0.997
- F1-score: 0.998
- Per la label Car del primo dataset la confusion matrix è la seguente:

Figura 3: Confusion Matrix Car del primo dataset
Per la label Car si ha:
- Precision: 0.865
- Recall: 0.870
- F1-score: 0.868
Adesso a seguire ci saranno le confusion matrix del secondo dataset.
- Per la label BG del secondo dataset la confusion matrix è la seguente:

Figura 4: Confusion Matrix BG del secondo dataset
Per la label BG si ha:
- Precision: 0.323
- Recall: 0.444
- F1-score: 0.374
- Per la label traffic-light del secondo dataset la confusion matrix è la seguente:

Figura 5: Confusion Matrix traffic-light del secondo dataset
Per la label traffic-light si ha:
- Precision: 1
- Recall: 0.892
- F1-score: 0.942
- Per la label Car del secondo dataset la confusion matrix è la seguente:

Figura 6: Confusion Matrix Car del secondo dataset
Per la label Car si ha:
- Precision: 1
- Recall: 0.784
- F1-score: 0.879
- Per la label Person del secondo dataset la confusion matrix è la seguente:

Figura 7: Confusion Matrix Person del secondo dataset
Per la label Person si ha:
- Precision: 0.652
- Recall: 0.773
- F1-score: 0.707
Calcolo F-score
Nel codice sottostante viene mostrato il metodo per il calcolo del F-score, della mean Average Precision (mAP) e della mean Average Recall (mAR).
def evaluate_model2(dataset, model, cfg):
APs = list();
ARs = list();
F1_scores = list();
for image_id in dataset.image_ids:
image, image_meta, gt_class_id, gt_bbox, gt_mask = load_image_gt(dataset, cfg, image_id)
scaled_image = mold_image(image, cfg)
sample = expand_dims(scaled_image, 0)
yhat = model.detect(sample, verbose=0)
r = yhat[0]
AP, precisions, recalls, overlaps = compute_ap(gt_bbox, gt_class_id, gt_mask, r["rois"], r["class_ids"], r["scores"], r['masks'])
AR, positive_ids = compute_recall(r["rois"], gt_bbox, iou=0.2)
ARs.append(AR)
F1_scores.append((2* (np.mean(precisions) * np.mean(recalls)))/(np.mean(precisions) + np.mean(recalls)))
APs.append(AP)
mAP = np.mean(APs)
mAR = np.mean(ARs)
return mAP, mAR, F1_scores
mAP, mAR, F1_scores= evaluate_model2(dataset, model, config)
print("mAP: %.3f" % mAP)
print("mAR: %.3f" % mAR)
print("first way calculate f1-score: ", np.mean(F1_scores))
F1_score_2 = (2 * mAP * mAR)/(mAP + mAR)
print('second way calculate f1-score_2: ', F1_score_2)Per il primo dataset i risultati sono stati:
- mAP: 0.554
- mAR: 0.699
- f-score: 0.6182087488839708
Invece per il secondo dataset sono stati:
- mAP: 0.307
- mAR: 0.364
- f-score: 0.3332826754404349
Conclusione
Nel corso di questa tesi, abbiamo condotto un’analisi approfondita di due dataset distinti. Il primo dataset, che abbiamo definito come ‘facile’, ha presentato caratteristiche più semplici e meno variabili. Il secondo dataset, definito come ‘complesso’, era più complesso e presentava una maggiore variabilità nei dati.
Attraverso l’uso di vari modelli di machine learning, abbiamo calcolato l’F-score per entrambi i dataset. Come previsto, il dataset ‘facile’ ha mostrato un F-score significativamente più alto rispetto al dataset ‘complesso’. Questo suggerisce che il modello ha avuto meno difficoltà a fare previsioni accurate sul dataset ‘facile’.
Tuttavia, nonostante la differenza negli F-score, entrambi i modelli hanno fornito intuizioni preziose. L’analisi del dataset ‘complesso’ ha rivelato aree in cui il modello potrebbe essere migliorato, fornendo una direzione preziosa per la ricerca futura.
In conclusione, questa tesi ha dimostrato l’importanza dell’analisi dei dati e della valutazione del modello nel campo del machine learning. Nonostante le sfide presentate dal dataset ‘complesso’, i risultati ottenuti offrono un punto di partenza promettente per ulteriori miglioramenti e ricerche.